1. Kafka - 논문
Kafka: a Distributed Messaging System for Log Processing, LinkedIn Corp. 2011
예전 논문이지만 Kafka의 기본 원리나 내부 구조를 알 수 있을거라 생각하고 해당 논문 내용을 정리한다.
1. Introduction
it 회사에는 많은 양의 로그 데이터가 존재한다.
- 유저의 입력 이벤트 ex) 로그인, 페이지 뷰, 클릭, 좋아요, 댓글, 공유, 검색 쿼리 등...
- 운영 메트릭 데이터 ex) 서비스 콜 스택, 에러, 시스템 메트릭 (CPU, 메모리, 네트워크, 저장소 사용량 등)
최신 동향은 이런 로그 데이터들을 다음과 같은 분야에 활용한다.
- 검색 추천? (search relevance)
- 광고 타게팅 및 리포트
- 어뷰징 활동으로 부터 방어 (스팸 메시지 등)
- 뉴스피드
검색 추천이나 광고에서는 유저의 클릭 로그를 생성해야하고, 심지어 클릭하지 않은 아이템도 기록으로 남겨서 활용한다. (매일 대략 6TB 모은다는데 2011 기준임)
기존에 만들어진 시스템들은 물리적으로 프로덕션 서버의 로그를 긁어가고 있다.
최근 몇년동안, 분산 로그 수집 툴이 만들어졌는데, 페이스북의 Scribe, 야후의 Data Highway, 클라우데라의 Flume 등이 있다.
이런 시스템들은 로그를 모아서 데이터 창고 또는 Hadoop에 적재하는데 우선순위를 두고 디자인되었다. 적재하는 목적이 이후 데이터를 오프라인 소비(offline consumption?)하기 위함이라는데... 저장해두고 이후에 쿼리해서 유의미한 데이터로 가공하는 느낌? 실시간이 아닌 것을 offline이라 말하는 것으로 보인다.
링크드인(sns)에서는 전통적인 offline analytics에 더하여 실시간 시스템을 지원해야 했다.
Kafka라는 로그 처리 메시지 시스템을 만들었고, 전통적인 로그 수집 및 메시지 시스템의 장점들을 합쳤다.
또한, 카프카는 분산처리 가능하고 확장가능하며, 높은 처리량을 제공한다.
메시지 시스템처럼 API를 제공하고 애플리케이션이 실시간으로 로그를 소비할 수 있게 한다.
링크드인에서 6개월동안 성공적으로 프로덕션 레벨에서 운영되었으며 오픈소스다.
심플한 구조를 가졌기에 소프트웨어 하나로 online, offline으로 모든 형태의 로그 데이터를 이용할 수 있다.
2. Related Work
다른 기존 시스템들 문제점
- 로그 전송 보장을 위해 과도한 설계
- 처리량의 한계
- 즉각적인 메시지 소비를 가정
3. Kafka Architecture and Design Principles
topic: 특정 타입의 메시지 스트림producer는 메세지들을 topic에 게재
게재된 메시지들은 broker라는 서버에 저장consumer는 broker로부터 한 개 이상의 topic들을 구독 가능하고, 데이터를 받아와서 사용할 수 있다.
메시징은 간단한 컨셉, Kafka API 도 이와 동일하게 간단하게 만드려고 노력했다.
메시지는 단순하게 바이트로 이뤄짐, serialization 방식은 각자 알아서 정하면 된다. (string, json, avro, protobuf..)
효율을 위해서 producer는 단일 게재 요청에 여러개의 메시지를 전송할 수 있다.
topic을 구독하기 위해서, consumer는 먼저 메시지 스트림을 만들어야 한다.
topic에 게재된 메시지들은 이 서브 메시지 스트림들로 균일하게 분포된다.
각각의 메시지 스트림은 iterator interface를 제공한다. consumer는 스트림에서 모든 메시지들을 iterate 하면서 데이터를 처리한다.
전통적인 iterator 들과는 달리, 메시지 스트림 iterator는 절대 끝나지 않는다.
현재 더 이상의 메시지가 없는 경우 iterator는 새로운 메시지가 게재될 때까지 막기만한다. => consumer가 새로운 데이터(이벤트)가 들어올 때 까지 지속적으로 대기할 수 있도록 함
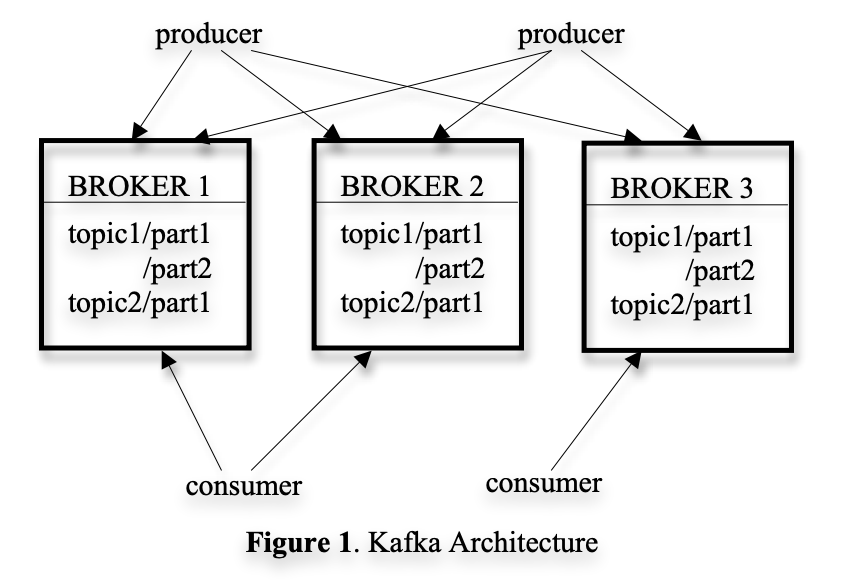
카프카 클러스터는 전형적으로 여러개의 broker를 가지고 있다.
골고루 적재하기 위해, topic은 여러개의 파티션으로 나눠져있고, 각각의 broker는 여러개의 파티션을 저장하고 있다.
복수의 producer와 consumer가 동시에 게재(producing)하고 메시지를 가져올 수 있다. (여러 개의 producer가 동시에 게재하고 여러개의 consumer가 동시에 메시지를 가져온다는 듯)
3.1 Efficiency on a Single Partition
Simple storage
카프카는 매우 간단한 저장소를 가짐.
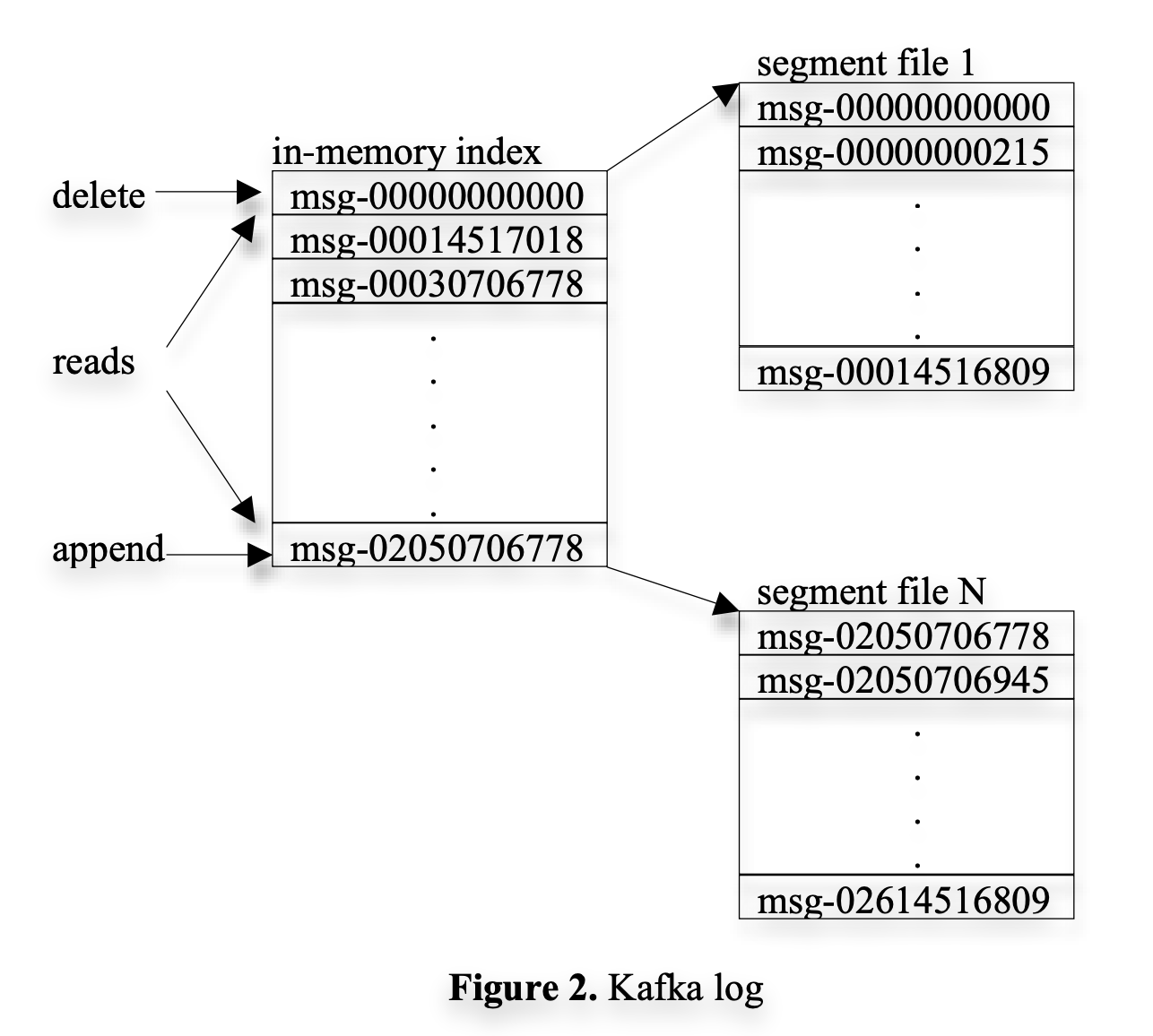
각 topic의 파티션들은 논리적 로그에 해당 로그는 대략 비슷한 사이즈의 세그먼트 파일들의 집합으로 구성된다.
매 순간 producer는 파티션에 메시지를 게재하고, broker는 단순하게 마지막 세그먼트 파일에 메시지를 이어 붙인다.
더 나은 성능을 위해, 세그먼트 파일을 설정한 개수 이상의 메시지들이 게재되었을 때, 혹은 일정 시간이 지난 후에 디스크에 저장한다.
메시지는 디스크에 저장된 후에 consumer에게 노출된다.
이전 메시지 시스템들과 달리, 카프카에서는 메시지 아이디 (아마 index를 뜻하는듯?)를 따로 가지진 않는다.
대신에, 각 메시지들은 offset을 가지고 저장(addressed)된다. 이로써 무작위 탐색 index 구조의(maintaining auxiliary, seek-intensive random-access index structures?) 오버헤드를 피하게 된다. 인덱스를 저장하면 그에 따라, 인덱스-실 주소 매핑 데이터도 가져야하기에 오버헤드가 발생.
카프카의 메시지 아이디는 증분하지만 연속적이지 않다. 다음 메시지 아이디를 계산하기 위해서는 현재 메시지 아이디에서 메시지의 길이만큼 더해야 한다. (그냥 배열 생각하면 되는?)
=> 메시지 순차적 접근이라는 가정하에 설계한 듯 하다. 요구사항이 만약 무작위 접근이라면 매번 offset으로 계산하는게 오히려 오버헤드 발생할 것.
consumer는 항상 특정 파티션에서 일련의 메시지들을 소비한다. consumer가 특정 메시지의 offset을 안다는 것은 해당 파티션에서 해당 메시지 앞에 존재했던 모든 메시지들을 소비했다는 뜻.
consumer는 브로커에게 애플리케이션이 소비할 준비가 완료된 데이터들의 버퍼를 얻기 위해 비동기적으로 요청을 발행한다.
각각의 요청들은 소비를 시작하려는 메시지에 대한 offset과 fetch 가능한 (가져올 수 있는) 바이트 수를 포함한다.
각 broker들은 메모리에 모든 세그먼트 파일 첫번째 메시지의 offset들을 정렬하여 저장하고 있다. broker는 offset 목록을 검색해서 요청된 메시지가 있는 세그먼트 파일을 찾아 consumer에게 응답한다.
consumer는 메시지를 받은 후, 다음에 사용할 메시지의 offset을 계산한다.
Efficient transfer
데이터 전송에 대해서 많은 신경을 썼다. producer는 여러 메시지들을 한 번에 전송 가능하다.
각 요청에서 consumer가 특정 사이즈 범위 내의 메세지 집합을 한 번에 받을 수 있지만, consumer가 최종적으로는 한 번에 하나의 메시지만 확인 가능하다.
또 다른 차이점은 카프카에서는 메시지를 메모리에 캐싱하지 않는다는 것이다. (JVM 힙 메모리에 캐시되는걸 명시적으로 회피)
대신 파일 시스템 페이지 캐싱에 의존한다. 메시지들이 페이지 캐시에만 캐싱됨으로 더블 버퍼링을 피할 수 있다는 가장 큰 장점이 있다.
추가적으로 broker프로세스가 재시작된다고 해도 warm 캐시는 유지된다는 장점이 있다.
추가로 consumer의 네트워크 접근을 효율화했다. 카프카는 multi-subscriber system 이고 하나의 메시지는 여러 consumer에 의해 소비될 수 있다.
전형적인 (로컬 파일에서 원격 소켓까지의) 데이터 전송 단계는 다음과 같다.
- 저장소에서 페이지 캐시로 데이터를 읽는다, in OS
- 페이지 캐시에서 어플리케이션 버퍼로 데이터를 복사
- 어플리케이션 버퍼에서 다른 커널 버퍼로 복사
- 커널 버퍼에서 소켓으로 전송
이 과정에서 4번의 데이터 복사와 2번의 시스템 콜이 일어난다.
리눅스나 다른 유닉스 운영체제에서는 파일 채널에서 소켓 채널까지 바로 데이터 전송할 수 있는 API를 제공한다.
이는 (2), (3)에서 일어난 2번의 데이터 복사와 1번의 시스템 콜을 줄일 수 있다.
카프카는 이 API를 사용하여 broker의 로그 세그먼트 파일에서 consumer까지 효율적으로 데이터 전송한다.
Stateless broker
다른 메시징 시스템들과 달리, 카프카에서는 각 consumer가 얼마나 메시지를 소비했는지 broker에서 관리하지 않는다, consumer가 각자 관리한다. 이러한 설계는 브로커의 복잡성과 오버헤드를 줄인다.
반면에 이러한 설계는 메시지 삭제를 어렵게 만드는데, broker가 모든 구독자들이 메시지를 소비했는지 알 수 없기 때문이다.
카프카는 이 문제를 간단한 time-based SLA를 사용하여 해결했다. 메시지는 일정 기간(7d)이 지나면 자동으로 삭제된다.
이 해결 방법은 실제 사용에도 잘 동작한다. 오프라인까지 포함하여 대부분의 consumer들은 메시지 소비를 하루안에 끝낸다.
=> broker는 그냥 offset 받는대로 읽는 역할, kafka group coordinator가 offset을 관리(__consumer_offsets 라는 토픽에 offset 저장)
consumer: offset 커밋 주체
kafka group coordinator: offset 저장 및 관리 (명시적으로 offset을 요청받지 않으면 저장된 offset을 전달)
broker : 오프셋부터 데이터 읽기
이 설계에는 또 다른 중요한 장점이 있다. consumer는 지난 offset을 전송함으로써 데이터를 다시 받을 수 있다.
이는 일반적인 큐의 룰을 깨지만, consumer의 중요한 특징들을 보장한다.
예를 들어 어플리케이션 로직에서 에러가 발생한 경우, 어플리케이션은 에러 이후 다시 해당 메시지들로 로직들 다시 돌려봄으로써 에러를 해결할 수 있다.
또 다른 예를 들어, 소비된 데이터는 영구적 저장소에 오직 주기적으로만 저장된다. 만약 consumer가 충돌나면, 저장되지 않은 데이터는 날라간다. 이 경우 consumer는 다시 시작했을 때, 저장되지 않은 메시지 중 가장 작은 offset으로 부터 다시 시작하면서 해당 offset으로 부터 다시 메시지 소비할 수 있다.
consumer를 다시 되돌리는 것에 대해 pull model(컨슈머가 메시지 가져가는)이 push model(프로듀서가 메시지를 넣는)보다 더 쉽다. (=어디까지 성공적으로 메시지가 처리되었는지는 consumer가 잘 알기 때문)
Distributed Coordination
지금까지 producer와 consumer들이 분산된 환경에서 어떻게 행동하는지 설명했다.
producer는 파티셔닝 키를 통해 무작위로 선택된 파티션에 메시지를 개제하거나 파티셔닝 로직에 의해 의도적으로 결정된 파티션에 메시지를 개제할 수 있다.
어떻게 consumer가 broker와 소통하는지 설명하겠다.
카프카에는 consumer group이라는 개념이 존재한다.
각각의 consumer group은 하나 이상의 consumer를 가지고 있다. 하나의 그룹 내 consumer들은 공동으로 topic집합을 소비한다.
예를 들어, 메시지는 그룹 중 하나의 consumer에게만 전달된다. consumer group 들은 각자 독립적으로 메시지를 소비하며 그룹 간 조율은 필요없다.
같은 그룹 내 consumer 들은 각기 다른 프로세스 또는 기기에 포함될 수 있다. 우리의 목표는 조율에 많은 오버헤드 없이, broker에 저장된 메시지들을 그룹 내 각각의 consumer에 골고루 분산하는 것이다.
우리의 첫번째 결정은 토픽을 병렬적으로 파티셔닝하는 것이다. 이는 언제든지, 하나의 파티션에서 온 모든 메시지들은 각각의 consumer group의 한 consumer에서 소비된다는 것을 의미한다. 여러 consumer 들이 동시에 하나의 파티션을 소비할 수 있으니, 누가 어떤 메시지를 소비할 건지 조율하는 부분이 필요하고, 이에 락이나 상태 보전을 위한 오버헤드가 일어난다.
반면에, 우리의 설계에서 메시지 소비 과정은 consumer가 적재를 재배치할 때만 조율이 필요하다. 적재가 균일하게 재배치되기 위해, 우리는 각 그룹의 consumer 수 보다 한 토픽에 대한 파티션이 많이 필요하다. 우리는 단순히 토픽을 많이 파티셔닝해서 이 목표를 이룰 수 있다.
두번째 결정은 중앙 집중적인 master 노드를 만들지 않고, consumer끼리 조율하게 해서 탈중앙화하는 것이다. 마스터를 만드는 것은 마스터가 실패할 경우에 대해 대응해야 해서 시스템을 복잡하게 만들 수 있다. 조율을 용이하게 하기 위해, 고가용성 조율 서비스 Zookeeper 를 사용했다.
path를 만들고, path의 값을 정하고, path의 값을 읽고, path를 삭제하고, path의 자식들을 리스트업할 수 있다. 이것은 여러가지 흥미로운 일을 하게 하는데,
- path에 대해 감시자를 등록하고, path의 자식들이나 path의 값이 변경되었을 때 알림을 받을 수 있다.
- path는 비영구적으로 생성될 수 있는데, 이는 생성자가 사라지면 path는 Zookeeper 서버에 의해 자동으로 삭제된다는 것을 뜻한다.
- 데이터를 여러 서버에 복제해두어서 고가용성을 가지고 있다.
카프카는 주키퍼를 다음 용도로 사용한다.
- broker나 consumer의 삭제나 추가를 탐지
- (1)이벤트에 의한 consumer의 재배치 처리를 트리거
- 소비 관계 유지 및 각 파티션의 소비 offset 추적
특히, broker나 consumer가 시작됐을 때, 주키퍼에 등록 정보를 저장한다. broker는 호스트 이름 및 포트, 토픽들과 그에 저장된 파티션들에 대한 등록 정보를 주키퍼에 저장한다. consumer는 본인이 속한 consumer group과 구독중인 토픽에 대한 등록 정보를 주키퍼에 저장한다. 각각의 consumer group은 소유자 등록 정보, offset 등록 정보를 저장한다. 소유자 등록 정보는 모든 구독중인 파티션마다 하나의 path를 가지고 있고, 해당 path의 값은 해당 파티션을 소비중인 consumer의 id다. ( consumer가 파티션을 소유 중이라는 용어를 쓴다.) offset 등록 정보는 각 구독중인 파티션의 정보와 파티션에서 가장 최근 소비한 메시지의 offset 정보다.
위 설명한 등록 정보 중 offset 등록 정보만 영구적이고, 나머지 등록 정보는 모두 비영구적이다. broker가 실패한 경우 해당 브로커의 모든 파티션들은 자동으로 브로커 등록 정보로부터 삭제된다. consumer의 실패는 컨슈머 등록정보와 해당 consumer가 가진 소유자 등록 정보(어떤 파티션을 소유중인지)를 삭제하도록 한다. 각 consumer 는 주키퍼 감시자를 등록하여 broker 등록 정보와 consumer 등록 정보를 감시하도록 하여, broker 나 consumer group이 변경될 경우 바로 감지할 수 있다.
consumer가 시작하는 동안이나 broker/consumer가 변경되었다는 알림을 받은 경우 consumer는 새로운 파티션 서브셋을 결정하기 위해 재배치 프로세스를 시작한다. 재배치 프로세스는 다음 그림과 같다.

주키퍼로부터 consumer, broker 등록정보를 읽어서, 토픽 T를 구독 가능한 파티션 집합(Pt)을 계산하고, 토픽 T를 구독중인 컨슈머(Ct)들을 계산한다. Pt를 Ct 집합에 파티셔닝 할 수 있고, 결정적으로 소유할 한 집합을 선택 할 수 있다. (토픽 하나를 구독 가능한 많은 파티션들이 컨슈머 개수만큼 쪼개져서 묶이고 컨슈머는 묶여있는 파티션 집합 하나를 소유하게 되는?)
consumer가 선택한 각각의 파티션에 대해, consumer는 자기 자신을 파티션의 소유자라고 소유자 등록정보에 저장한다.
최종적으로는 컨슈머는 소유한 파티션들로부터 메시지 읽기를 시작하게 된다. 해당 데이터 풀은 offset 등록 정보에 저장된 offset으로 부터 시작한다. 메시지들이 파티션으로부터 불러와지면서 consumer는 주기적으로 최신 소비 offset을 offset 등록 정보에 업데이트한다.
한 그룹에 여러 consumer가 있을 때, 각각의 consumer는 브로커나 컨슈머의 변경사항을 각각 알림 받을 것이다. 하지만, 각각의 알림은 약간의 시간 차이가 있다. 따라서 한 consumer가 다른 consumer의 파티션을 소유하려고 시도할 수 있다. 이 경우, 첫번째 consumer가 현재 소유중인 모든 파티션을 풀어주고, 잠깐 기다린 다음 재배치 프로세스를 다시 시도한다. 실제로 재배치 프로세스는 종종 몇번의 재시도 이후에 안정되기도 한다.
새로운 컨슈머 그룹이 만들어졌을 때, offset 등록정보에 사용 가능한 offset 정보가 없다. 이 경우, 컨슈머들은 설정에 따라 구독중인 파티션에서 가능한 가장 작은 offset 또는 큰 offset으로부터 메시지 읽기를 시작한다.
3.3 Delivery Guarantees
카프카는 최소 한 번의 전송만을 보장한다. 한번의 전송은 두 단계의 커밋이 필요하지만 카프카에서는 아니다. 대부분의 경우 메시지는 정확히 각각의 컨슈머 그룹에 한 번만 전송된다. 하지만, 깔끔한 종료 없이 컨슈머 프로세스가 충돌나는 경우, 실패된 컨슈머가 가진 파티션을 인계받으려는 컨슈머 프로세스가 주키퍼에 커밋된 마지막 offset 이후의 메시지를 중복으로 받을 수도 있다. 애플리케이션이 중복에 대해서 대응해야 하는 경우, 컨슈머에게 반환한 오프셋을 사용하거나 메시지에 고유 키를 사용하여 해당 애플리케이션 자체적으로 대응 로직을 세워야 한다. 이것이 2단계 커밋을 사용하는 것보다 효율적이다.
카프카는 단일 파티션으로 부터 온 메시지의 순서를 보장한다. 반면에 다른 파티션들로 부터 온 메시지들에 대한 순서는 보장하지 못한다.